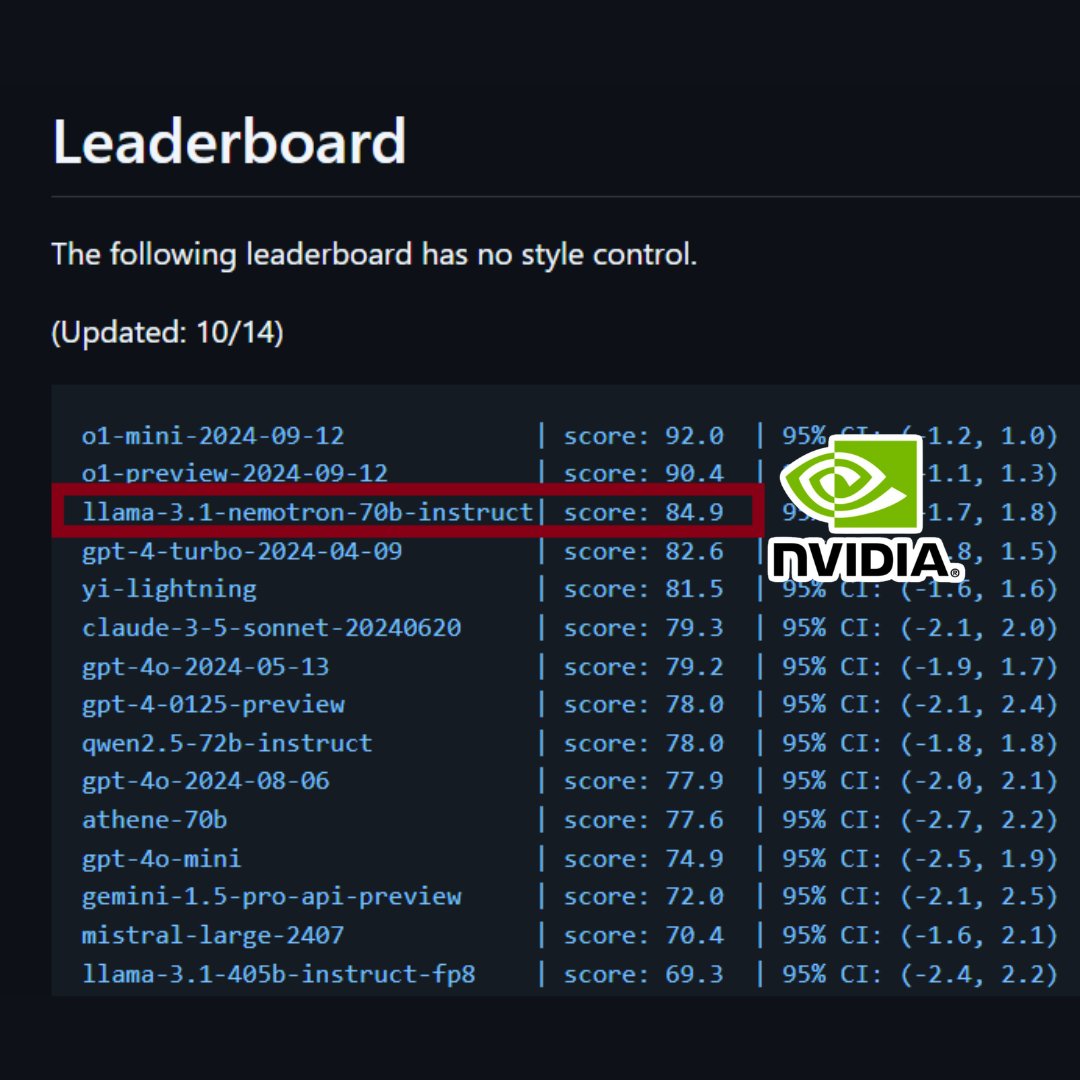
🥤 Cola [NeurIPS 2023]
Large Language Models are Visual Reasoning Coordinators
Liangyu Chen*,†,♥ Bo Li*,♥ Sheng Shen♣ Jingkang Yang♥
Chunyuan Li♠ Kurt Keutzer♣ Trevor Darrell♣ Ziwei Liu✉,♥
♥S-Lab, Nanyang Technological University
♣University of California, Berkeley ♠Microsoft Research, Redmond
*Equal Contribution †Project Lead ✉Corresponding Author... See more
Large Language Models are Visual Reasoning Coordinators
Liangyu Chen*,†,♥ Bo Li*,♥ Sheng Shen♣ Jingkang Yang♥
Chunyuan Li♠ Kurt Keutzer♣ Trevor Darrell♣ Ziwei Liu✉,♥
♥S-Lab, Nanyang Technological University
♣University of California, Berkeley ♠Microsoft Research, Redmond
*Equal Contribution †Project Lead ✉Corresponding Author... See more
cliangyu • GitHub - cliangyu/Cola: [NeurIPS2023] Official implementation of the paper "Large Language Models are Visual Reasoning Coordinators"
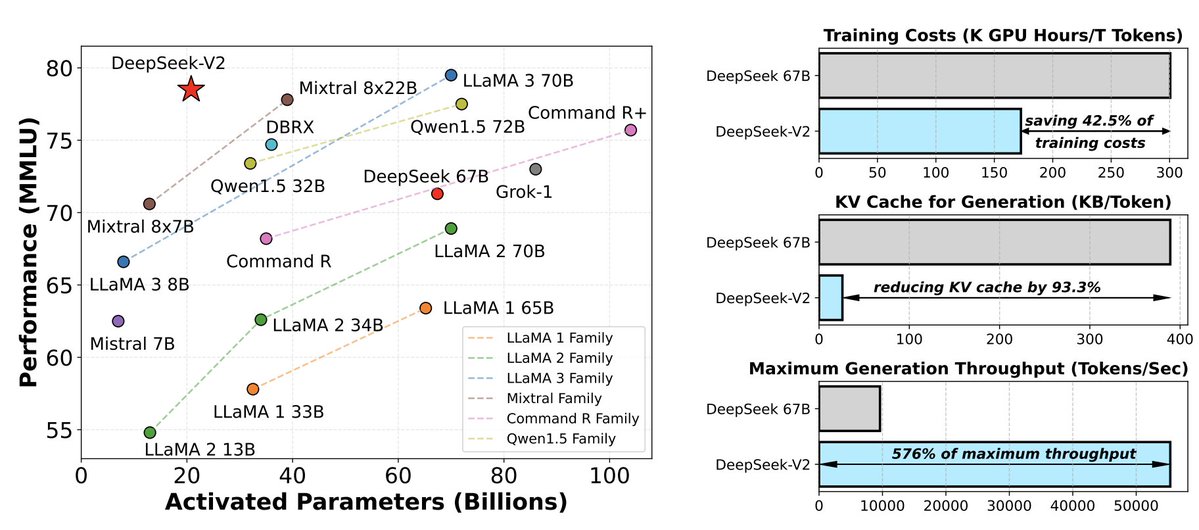
DeepSeekV2 is a big deal. Not only because its significant improvements to both key components of Transformer: the Attention layer and FFN layer.
It has also completed disrupted the Chines LLM market and forcing the competitors to drop the price to 1% of the original price.
⬇️ https://t.co/eDNeRHAzTp
LLaVA v1.5, a new open-source multimodal model stepping onto the scene as a contender against GPT-4 with multimodal capabilities. It uses a simple projection matrix to connect the pre-trained CLIP ViT-L/14 vision encoder with Vicuna LLM, resulting in a robust model that can handle images and text. The model is trained in two stages: first, updated ... See more