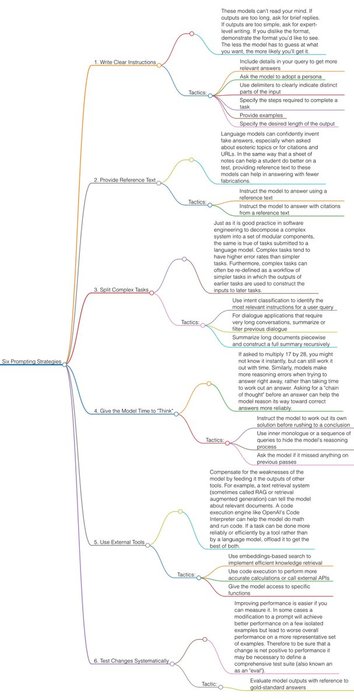
Open AI released a great Prompt Engineering guide (link in comments).
Here is a summary of their 6 strategies for getting better results when prompting GPT-4 https://t.co/QiBASsbOHD
Evaluating Large Language Models (LLMs) as agents in interactive environments, highlighting the performance gap between API-based and open-source models, and introducing the AgentBench benchmark.
W&B Prompts – LLM Monitoring provides large language model usage monitoring and diagnostics. Start simply, then customize and evolve your monitoring analytics over time.