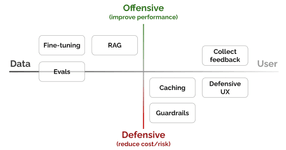
Improving RAG: Strategies
The way that most RLHF is done to date has the entire response from a language model get an associated score. To anyone with an RL background, this is disappointing, because it limits the ability for RL methods to make connections about the value of each sub-component of text. Futures have been pointed to where this multi-step optimization comes at... See more
Nathan Lambert • The Q* hypothesis: Tree-of-thoughts reasoning, process reward models, and supercharging synthetic data
a couple of the top of my head:
- LLM in the loop with preference optimization
- synthetic data generation
- cross modality "distillation" / dictionary remapping
- constrained decoding