GitHub - run-llama/llama-hub: A library of data loaders for LLMs made by the community -- to be used with LlamaIndex and/or LangChain
LLM-PowerHouse: A Curated Guide for Large Language Models with Custom Training and Inferencing
Welcome to LLM-PowerHouse, your ultimate resource for unleashing the full potential of Large Language Models (LLMs) with custom training and inferencing. This GitHub repository is a comprehensive and curated guide designed to empower developers, researche... See more
Welcome to LLM-PowerHouse, your ultimate resource for unleashing the full potential of Large Language Models (LLMs) with custom training and inferencing. This GitHub repository is a comprehensive and curated guide designed to empower developers, researche... See more
ghimiresunil • GitHub - ghimiresunil/LLM-PowerHouse-A-Curated-Guide-for-Large-Language-Models-with-Custom-Training-and-Inferencing: LLM-PowerHouse: Unleash LLMs' potential through curated tutorials, best practices, and ready-to-use code for custom training and inferencing.
GitHub - MadcowD/ell: A language model programming library.
github.com
slowllama
Fine-tune Llama2 and CodeLLama models, including 70B/35B on Apple M1/M2 devices (for example, Macbook Air or Mac Mini) or consumer nVidia GPUs.
slowllama is not using any quantization. Instead, it offloads parts of model to SSD or main memory on both forward/backward passes. In contrast with training large models from scratch (unattainable... See more
Fine-tune Llama2 and CodeLLama models, including 70B/35B on Apple M1/M2 devices (for example, Macbook Air or Mac Mini) or consumer nVidia GPUs.
slowllama is not using any quantization. Instead, it offloads parts of model to SSD or main memory on both forward/backward passes. In contrast with training large models from scratch (unattainable... See more
okuvshynov • GitHub - okuvshynov/slowllama: Finetune llama2-70b and codellama on MacBook Air without quantization
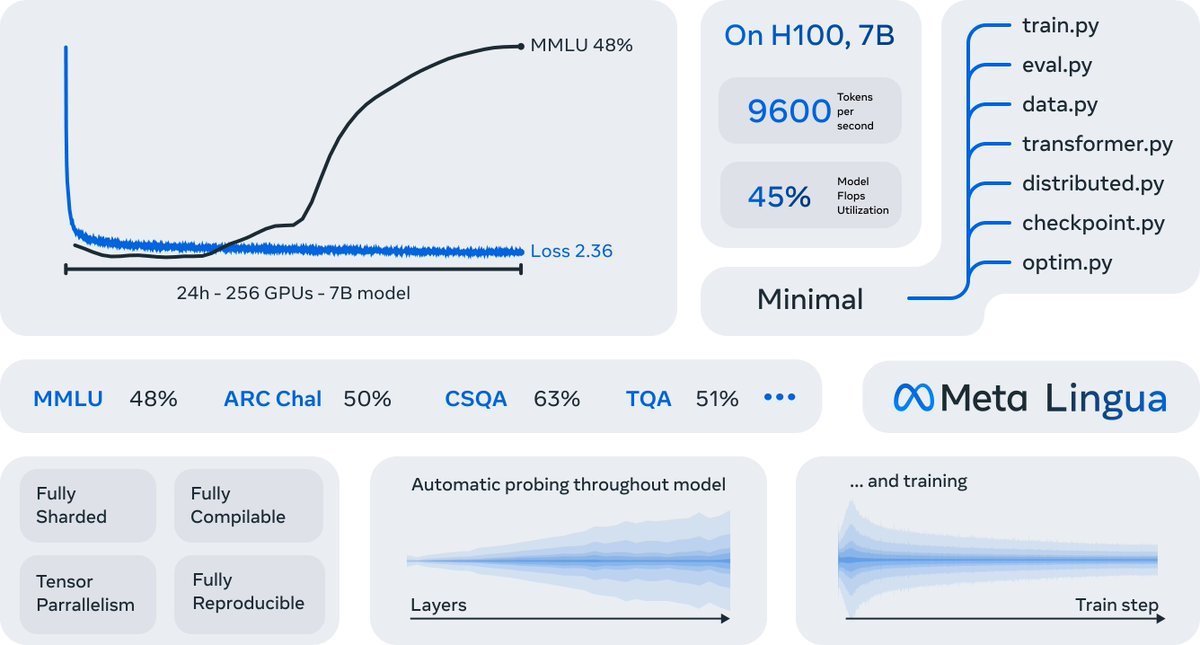
Meta 刚刚低调发布了一个最小且快速的 LLM大模型训练和推理框架库Meta Lingua。 目的是让更多人来训练 llama。可以 24 小时训练出一个 llama 7B,MMLU达到 48%。在许多下游任务上获得了非常强大的性能,并且与DCLM 基线 1.0的性能相匹配。
国内大模型要笑醒,训练一个国产大模型只需要 10 万人民币,费用计算: $2.50/h(租用一个 H100) × 256个(h100 gpu) × 24H = $15,360。
Meta Lingua主要特点 :
- 允许用户快速入门,而无需安装和配置大量依赖项。___LI... See more