GitHub - roboflow/multimodal-maestro: Effective prompting for Large Multimodal Models like GPT-4 Vision, LLaVA or CogVLM. 🔥
LLaVA v1.5, a new open-source multimodal model stepping onto the scene as a contender against GPT-4 with multimodal capabilities. It uses a simple projection matrix to connect the pre-trained CLIP ViT-L/14 vision encoder with Vicuna LLM, resulting in a robust model that can handle images and text. The model is trained in two stages: first, updated ... See more
This AI newsletter is all you need #68
Hands-on with Gemini: Interacting with multimodal AI
youtu.be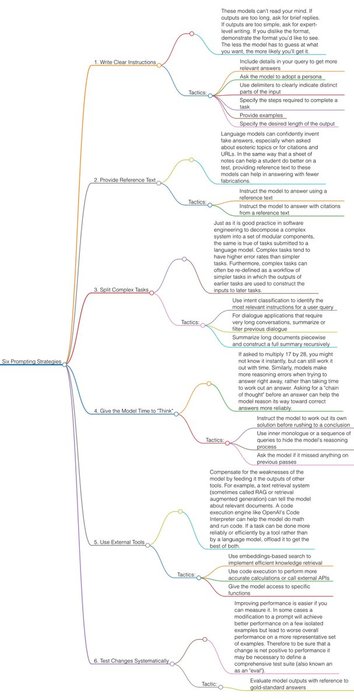
Open AI released a great Prompt Engineering guide (link in comments).
Here is a summary of their 6 strategies for getting better results when prompting GPT-4 https://t.co/QiBASsbOHD