Sublime
An inspiration engine for ideas
Deep-ML
deep-ml.com
🌳 Galileo LLM Studio
Algorithm-powered LLMOps Platform
Find the best prompt, inspect data errors while fine-tuning, monitor LLM outputs in real-time. All in one powerful, collaborative platform.
Testing framework for LLM Part
Taichi Lang: High-performance Parallel Programming in Python
taichi.graphics
🎄 lakera.ai
An Overview of Lakera Guard — Bringing Enterprise-Grade Security to LLMs with One Line of Code... See more
At Lakera, we supercharge AI developers by enabling them to swiftly identify and eliminate their AI applications’ security threats so that they can focus on building the most exciting applications securely.
Businesses around the world are in
Testing framework for LLM Part
⚡ LitGPT
Pretrain, finetune, evaluate, and deploy 20+ LLMs on your own data
Uses the latest state-of-the-art techniques:
✅ flash attention ✅ fp4/8/16/32 ✅ LoRA, QLoRA, Adapter (v1, v2) ✅ FSDP ✅ 1-1000+ GPUs/TPUs
Lightning AI • Models • Quick start • Inference • Finetune • Pretrain • Deploy • Features • Training recipes (YAML)
Finetune, pretrain and d... See more
Pretrain, finetune, evaluate, and deploy 20+ LLMs on your own data
Uses the latest state-of-the-art techniques:
✅ flash attention ✅ fp4/8/16/32 ✅ LoRA, QLoRA, Adapter (v1, v2) ✅ FSDP ✅ 1-1000+ GPUs/TPUs
Lightning AI • Models • Quick start • Inference • Finetune • Pretrain • Deploy • Features • Training recipes (YAML)
Finetune, pretrain and d... See more
Lightning-AI • GitHub - Lightning-AI/litgpt: Pretrain, finetune, deploy 20+ LLMs on your own data. Uses state-of-the-art techniques: flash attention, FSDP, 4-bit, LoRA, and more.

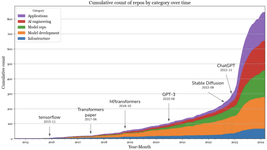
Mistral-finetune
mistral-finetune is a light-weight codebase that enables memory-efficient and performant finetuning of Mistral's models. It is based on LoRA, a training paradigm where most weights are frozen and only 1-2% additional weights in the form of low-rank matrix perturbations are trained.
For maximum efficiency it is recommended to use a A... See more
mistral-finetune is a light-weight codebase that enables memory-efficient and performant finetuning of Mistral's models. It is based on LoRA, a training paradigm where most weights are frozen and only 1-2% additional weights in the form of low-rank matrix perturbations are trained.
For maximum efficiency it is recommended to use a A... See more