Sublime
An inspiration engine for ideas
OpenAI
openai.com
OpenAI just dropped their Prompt Engineering guide.
Here are 6 strategies they recommend for getting better results from LLMs:
MatthewBermanx.com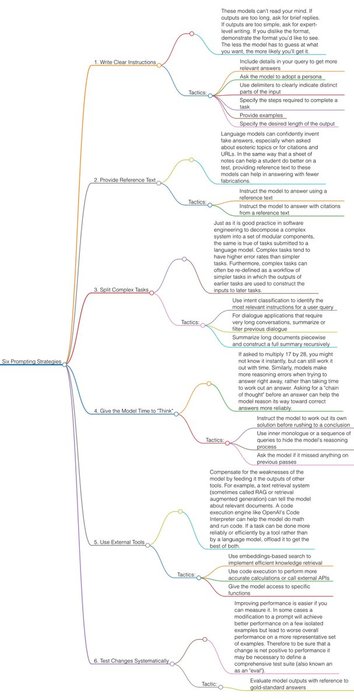
Open AI released a great Prompt Engineering guide (link in comments).
Here is a summary of their 6 strategies for getting better results when prompting GPT-4 https://t.co/QiBASsbOHD
🌳 Galileo LLM Studio
Algorithm-powered LLMOps Platform
Find the best prompt, inspect data errors while fine-tuning, monitor LLM outputs in real-time. All in one powerful, collaborative platform.
Testing framework for LLM Part




Deep-ML
deep-ml.com2-5x faster 50% less memory local LLM finetuning
- Manual autograd engine - hand derived backprop steps.
- 2x to 5x faster than QLoRA. 50% less memory usage.
- All kernels written in OpenAI's Triton language.
- 0% loss in accuracy - no approximation methods - all exact.
- No change of hardware necessary. Supports NVIDIA GPUs since 2018+. Minimum CUDA Compute Cap
unslothai • GitHub - unslothai/unsloth: 5X faster 50% less memory LLM finetuning

With many 🧩 dropping recently, a more complete picture is emerging of LLMs not as a chatbot, but the kernel process of a new Operating System. E.g. today it orchestrates:
- Input & Output across modalities (text, audio, vision)
- Code interpreter, ability to write & run… Show more